Making Grouped XML from CSV using Perl and SQL Scripting
Introduction
I had previously developed a complex database to XML translation solution for a consulting client of mine so they could translate data in a hierarchical SQL database on their Linux servers to XML formats so that it could be used for data modeling and easily imported into other applications. I chose Perl at the time because the client had the ability to run this on their Linux servers where their databases resided and then easily transport the result XML data models to their Windows and other applications. Perl scripts work well together on Linux systems so this was a good match.
For this project demo, I decided to strip about 90% of the code delivery solution and generalize the architecture and coding techniques I used to solve the problem of using Perl and embedded SQL to query a dataset, convert to XML, and output the results.
The Power of Perl

Perl is a scripting programming language that may be all forgotten or passed over with the beginner’s hype surrounding the easy to learn Python language. Take a little effort into learning the powers of Perl and you will find it is more capable in SQL, text manipulations, and a strong community of knowledgeable engineers that continuously add, update, and improve the language along with many additional modules (“libraries”) that you can import that expand or simplify the baseline code capabilities. Learn more about Perl here.
Architecture Mapping
Inputs
In this project, it assumes the dataset is in a simple CSV file. The first line of the CSV file is the header that contains the fields or columns of the data. The example file in the code repo (see bottom of page) is called input.csv and contains the entire dataset that we will be working with.
Here is the first row that contains the identifying fields or columns of information:

Let me briefly describe this dataset:
RECORD_ID: A positive integer value representing the record primary key or ID
MEMBER: A text-based identifier of which member category the data belongs to
COMPANY: A text-based identifier of which company category the data belongs to
AREA: This is the grouping identifier. A text field containing one of five categories (south, east, north, southeast, west). The record belongs to only one, not more of the categories. This AREA grouping field will be used to separate records into individual XML files based on their common AREA.
COLOR: A text-based identifier of what color code the data is (just for demo)
MODE: AUTO or MANUAL , text identifier of a state (just for the demo)
Here is an example of line 2 of the dataset:
746,Q,ABC_COMPANY,SOUTH,RED,AUTO
Outputs
The end result will be five individual XML files that correspond to the five possible AREA categories (remember we had AREA as the designated grouping field). If you were to add/modify records with more than five unique AREA categories, you would receive more group XML output files corresponding to the new AREA categories.
The example output files are shown in the code repo (see below for the link) with the following naming formats:

Each XML file has a planned pattern of modeling. You can easily modify the Perl script example for your own use to modify the XML output format. Here is overview look of the output XML with the details collapsed.
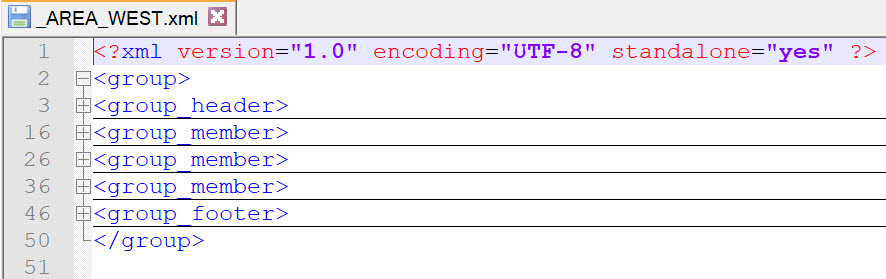
Each grouped output will have the same hierarchy but may have 1 or more group members, which correspond to the rows or records from our input CSV file that identified to this AREA group “West”. Not all AREA or grouped files may contain the same number or group members, it depends on the dataset involved.
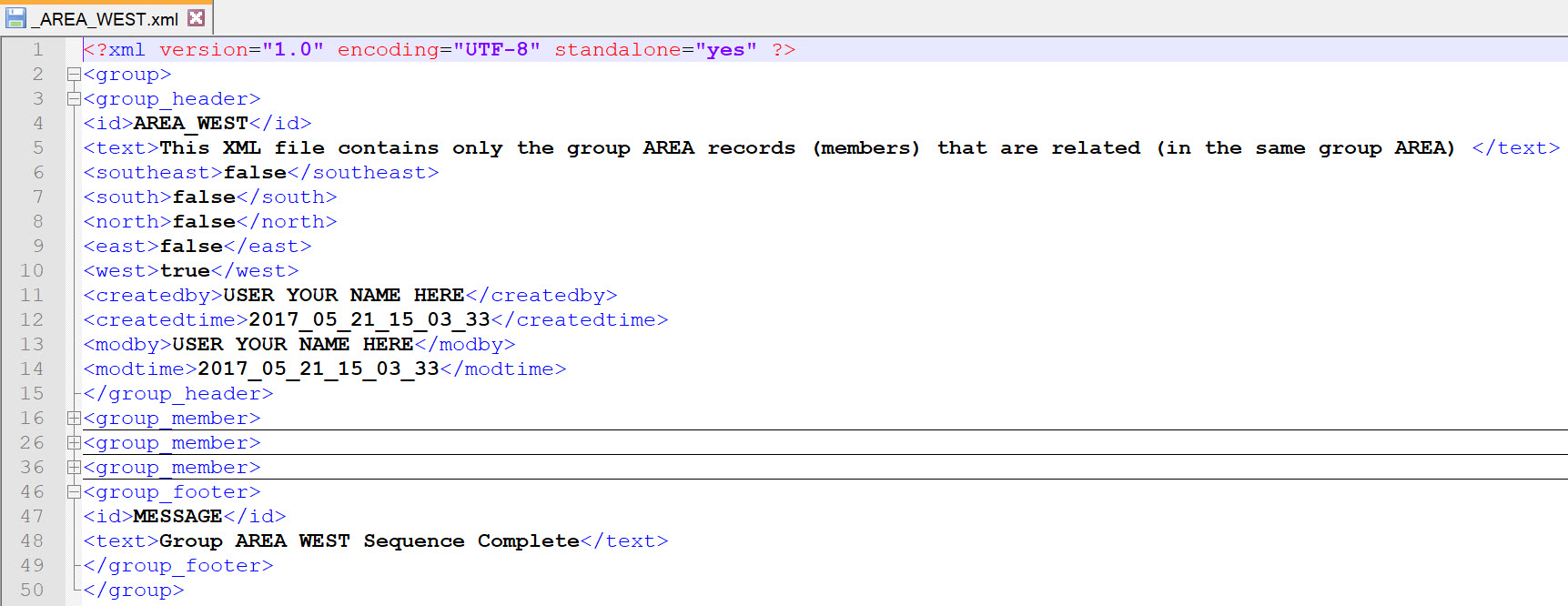
Each output file will contain a header and footer that describes the group data. The header and footer may be removed in your own implementation of the Perl script. Here are detail examples below for the WEST group.
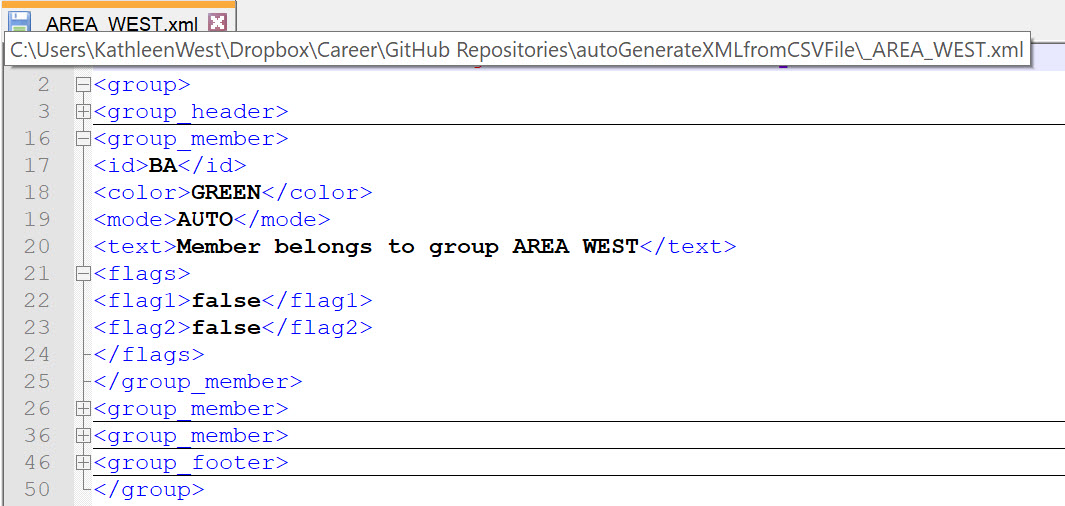
The XML file will contain 1 or more group members corresponding to the rows or records from the input CSV that were categorized to this AREA grouping field. Notice for this example, the output XML includes the remaining identifying fields from the record (color, mode, etc..) in XML format. There is some additional modeling information that was added to display some of the logic processing and ability to embed child XML information. The flag logic code will be described in the scripting section. All you need to know is that is does some business logic processing in the script based on the record’s contents, and displays the appropriate XML output.
Scripting
The main programming script for this project example is autoGenerateXMLfromCSVFile.pl which is included in the project code repo (see bottom of page). You may modify the scripting file for your personal or business objectives. This script discussion assumes basic familiarity with Perl. This project article is meant to “demo” and not “teach” a Perl project.
Perquisites
Perl installation and appropriate permissions to read/write to your working directory. Also, you may need to procure (free) additional modules for the time and DBA (SQL) functions. Here are the project module (library) dependencies:
use Time::Piece;
use DBI;
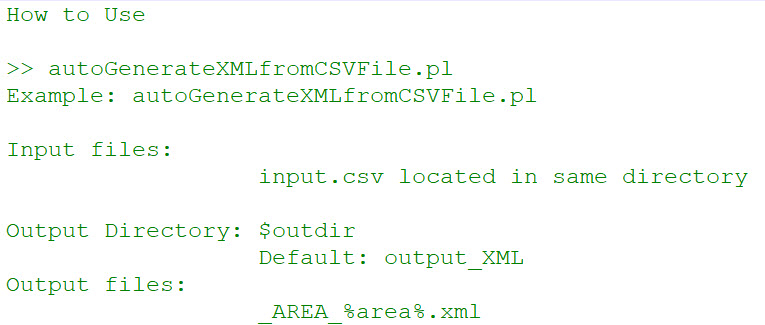
How to Use
Description of the File
#=======================================================================
# autoGenerateXMLfromCSVFile.pl
#=======================================================================
# Description: Perl script to create XML files for a select “grouping by”.
# The script considers a specified grouping field “AREA” in the input file
# as the select group by field and will create XML data based on that
# grouping field ID. The script uses a sample input file called input.csv and
# creates XML files by the AREA field group. The output file will be one XML
# for each group by field “AREA” with child XML nodes that correspond to
# records pulled from a database in each group by XML file AND that meet
# the SQL select by criteria (see bonus).
Bonus Examples
There is an example of how to query, select, and order by specific fields (COLOR and MODE in this example) DBI and SQL commands.
select AREA,MEMBER,COLOR,MODE from input.csv where COLOR like ‘GREEN%’ AND MODE like ‘AUTO%’ ORDER BY AREA,MEMBER
Code
The code project is not an open collaborative or maintained project, so please do not contact me regarding “improvements” other than bugs or corrections to my article and or information contained in the code repo.
Click here to access the project on my GitHub account.